Writing a Toy EDR for Linux
Table of Contents
tldr; simple proof of concept runtime security project for Linux. reads events via eBPF, and can detect some potentially malicious behavior. source
Problem
While competing in CCDC, defending systems against the illustrious red team, I found myself essentially going by a script. I would watch auth logs, tail service logs, keep an eye on listening ports, and check on all the running processes. And to add insult to injury, not only was I doing the same things over and over, I was doing them extremely poorly and inefficiently-- paging through ps auxf, investigating every listening port I didn't recognize in ss -plunt, and missing everything that would finish running faster than I could catch it. My weak human eyes have very limited throughput.
If only, instead of learning about baseline behavior of Linux myself, I could have a feed of all system calls made by all processes, then make automated decisions as to their legitimacy? Then I would be able to spend time investigating my services and completing injects, and responding to the (heavily filtered, and high signal to noise) alerts from those decisions. It would be like a blend of purely behavioral, strict, configured MAC kernel modules (ex., SELinux/Tomoyo) and mostly signature-based user space monitoring and antivirus tools. My dream was that I would git clone this project, run it, and be able to clock out of the competition. I didn't want to compile a kernel module, and I didn't want to recompile the kernel, and I wanted it to work on all (reasonable) versions.
As soon as I thought I could automate myself out, I started work on louis (summer 2020). The only problem was that I knew very little about Linux (the kernel), and had grossly inaccurate mental models of how processes and syscalls functioned. It's been over a year since I started and "finished" work, so, this post is a documentation of my failures and progress to a working demo, and on the way, having fun learning a bit about Linux.
Attempt 1
I knew that it was possible to use ptrace to puppet a process and intercept all of its syscall (and glibc function calls, or anything else, for that matter). So my plan was:
- Every time a new process is spawned...
- Attach to it with
ptrace... - And police its syscalls.
I started by optimistically watching the /proc directory with inotify. Then, I would be able to get new process creations without having to hook anything, or poll /proc every 100 milliseconds or something. Unfortunately, /proc is a pseudo-file system, which also means it's created as we read it, on the fly. So it's not updating by itself, and definitely won't be sending us any events via inotify.
Ok, fine, I'll poll /proc every tenth of a second. It can't be that bad, right? I refreshed my list of processes and checked for new ones, and slept for some delay. The issue with this became apparent when I would only catch nc -lvnp 4444 half the time: there was way too much latency. By the time the program called listen, it was a coin flip whether I had ptraced it or not. Something like this:
NC LOUIS
0.00 + (read /proc)
0.08 + exec
0.09 + _start
0.10 + (read /proc)
0.11 + listen (notice nc)
0.12 + ptrace attach
And when I expanded the scope of processes tracked, the second critical flaw was obvious, as my VM would lock up due to the extra resource requirements that come with essentially debugging every process on a system at once. Finally, being entirely user-space meant I could just... kill the process. Or even better, disable all ptrace with yama.ptrace_scope = 3. The anti-Louis program (redlouis.sh?1) could be a one-liner.
Attempt 2, 3, 4...
After fumbling through too many LWN articles (an amazingly high quality resource), I found two "new" technologies that may be more effective: ftrace and eBPF. ftrace looked very promising, but I read somewhere that it was uncommon to enable ftrace support when compiling the kernel. I interpreted that as it being unlikely a random CCDC image would have that functionality enabled. Having read more about it now, it seems like it may be much more common than I thought. Regardless, I went with eBPF since it was shiny, "safe"2, and promised that it would let me trace (and intercept!) any syscalls without resorting to rootkit shenanigans, and it would make my bed and butter my toast in the mornings.
So I got to work on using gobpf. In hindsight, it is some serious code smell to be including an entire C program as a string in my Go program, but let's ignore that for now. gobpf is super neat though. Let's say you want to trace all open calls (and you bet I did), you can modify their example code to do something like this:
1m := bcc.NewModule(`
2 #include <uapi/linux/ptrace.h>
3 #include <linux/sched.h>
4 #include <linux/fs.h>
5 #include <linux/fs_struct.h>
6 #include <linux/dcache.h>
7 BPF_PERF_OUTPUT(events);
8
9 struct event_t {
10 u32 uid;
11 u32 pid; // PID as in the userspace term (i.e. task->tgid)
12 u32 ppid; // Parent PID as in the userspace term (i.e. task->real_parent->tgid)
13 int retval;
14 int ret;
15 char pwd[128];
16 s16 dfd;
17 char filename[80];
18 int flags;
19 };
20
21 int syscall__openat(struct pt_regs *ctx,
22 int dfd,
23 const char __user *filename,
24 int flags,
25 umode_t mode)
26 {
27 struct event_t event = {};
28 struct task_struct *task;
29 task = (struct task_struct *)bpf_get_current_task();
30 event.pid = bpf_get_current_pid_tgid() >> 32;
31 event.ppid = task->real_parent->tgid;
32 bpf_probe_read_str(&event.filename, sizeof(event.filename), filename);
33 event.dfd = dfd;
34 event.flags = flags;
35 event.ret = ` + strconv.Itoa(eventNormal) + `;
36 events.perf_submit(ctx, &event, sizeof(struct event_t));
37 return 0;
38 }
39
40 int do_ret_sys_openat(struct pt_regs *ctx) {
41 struct event_t event = {};
42 struct task_struct *task;
43 task = (struct task_struct *)bpf_get_current_task();
44 event.pid = bpf_get_current_pid_tgid() >> 32;
45 event.ppid = task->real_parent->tgid;
46 event.retval = PT_REGS_RC(ctx);
47 event.ret = ` + strconv.Itoa(eventRet) + `;
48 events.perf_submit(ctx, &event, sizeof(event));
49 return 0;
50 }
51 `, []string{})
52defer m.Close()
53
54fnName := bcc.GetSyscallFnName("openat")
55
56openKprobe, err := m.LoadKprobe("syscall__openat")
57if err != nil {
58 ctx.Error <- newError(eventType, "failed to load get_return_value", err)
59 return
60}
61
62err = m.AttachKprobe(fnName, openKprobe, -1)
63if err != nil {
64 ctx.Error <- newError(eventType, "failed to attach return_value", err)
65 return
66}
67
68kretprobe, err := m.LoadKprobe("do_ret_sys_openat")
69if err != nil {
70 ctx.Error <- newError(eventType, "failed to load do_ret_sys_openat", err)
71 return
72}
73
74if err := m.AttachKretprobe(fnName, kretprobe, -1); err != nil {
75 ctx.Error <- newError(eventType, "failed to attach do_ret_sys_openat", err)
76 return
77}As you can see, they did all the hard work for us, we just had to glue it together with some C and gobpf Load and Attach calls.
While this code seemed to compile by itself, the main reason I took so many attempts to move on from this stage were the struggles I had with Go's module system. I wanted the architecture of the project to be a certain way, and that was not compatible with how Go did things. I'll spare you details from the time I spent reconciling the difference between the two, but I ended up with a structure that looked like this:
+------------+
| |
| CLI Output |
| |
+--------+---+
^
+-------------------------------------|------+
| | |
+--------+ | +---------+ +----------+ +---+---+ |
| | | | | | +---->+ | |
| | | | Sources +--->+ Analysis | | louis | |
| | eBPF | | | | | | | |
| Kernel +---------->+ Sockets | +----------+ +--+----+ |
| | | | Users | ^ ^ |
| | | | Proc... | +-------+ | | |
| | | | | | | | v |
+--------+ | +---------+ | Techs +<-+ +---+----+ |
| | | | Output | |
| +-------+ +--------+ |
| |
+--------------------------------------------+
Which translates to a file structure looking like:
.
├── analysis
│ ├── analysis.go
│ └── detections.go
├── correlate
│ ├── correlation.go
│ ├── explorers.go
│ └── search.go
├── events
│ ├── events.go
│ ├── exec.go
│ ├── listen.go
│ ├── open.go
│ └── ...
├── go.mod
├── go.sum
├── LICENSE
├── louis.go
├── output
│ └── output.go
├── system
│ ├── files.go
│ ├── network.go
│ └── processes.go
└── techs
├── l1001.go
├── l1002.go
├── l1003.go
├── ...
└── techs.go
Finally, I had a clean and "working" architecture.
Attempt 5
And thus, through the power of using libraries, I could listen to events! It was revolutionary. I could see all open (and openat) calls. It looked something like this (abridged):
root@devbox:~/opt/louis$ go build
root@devbox:~/opt/louis$ ./louis -v
open: /proc/self/cmdline
open: /etc/ld.so.cache
open: /lib/x86_64-linux-gnu/libc.so.6
open: /lib/x86_64-linux-gnu/libtinfo.so.6
open: /dev/tty
open: /usr/lib/locale/locale-archive
open: /etc/nsswitch.conf
open: /usr/bin/bash
open: /root/.terminfo
open: /etc/terminfo
open: /proc/self/cmdline
open: /etc/shadowThe output above is what it might look like if I ran bash and cat /etc/shadow. I could also capture the return values, which were all the parts I need! I was thrilled. I just needed to clean up the code a bit and write ~50 rules. But hey, it worked! Look at this:
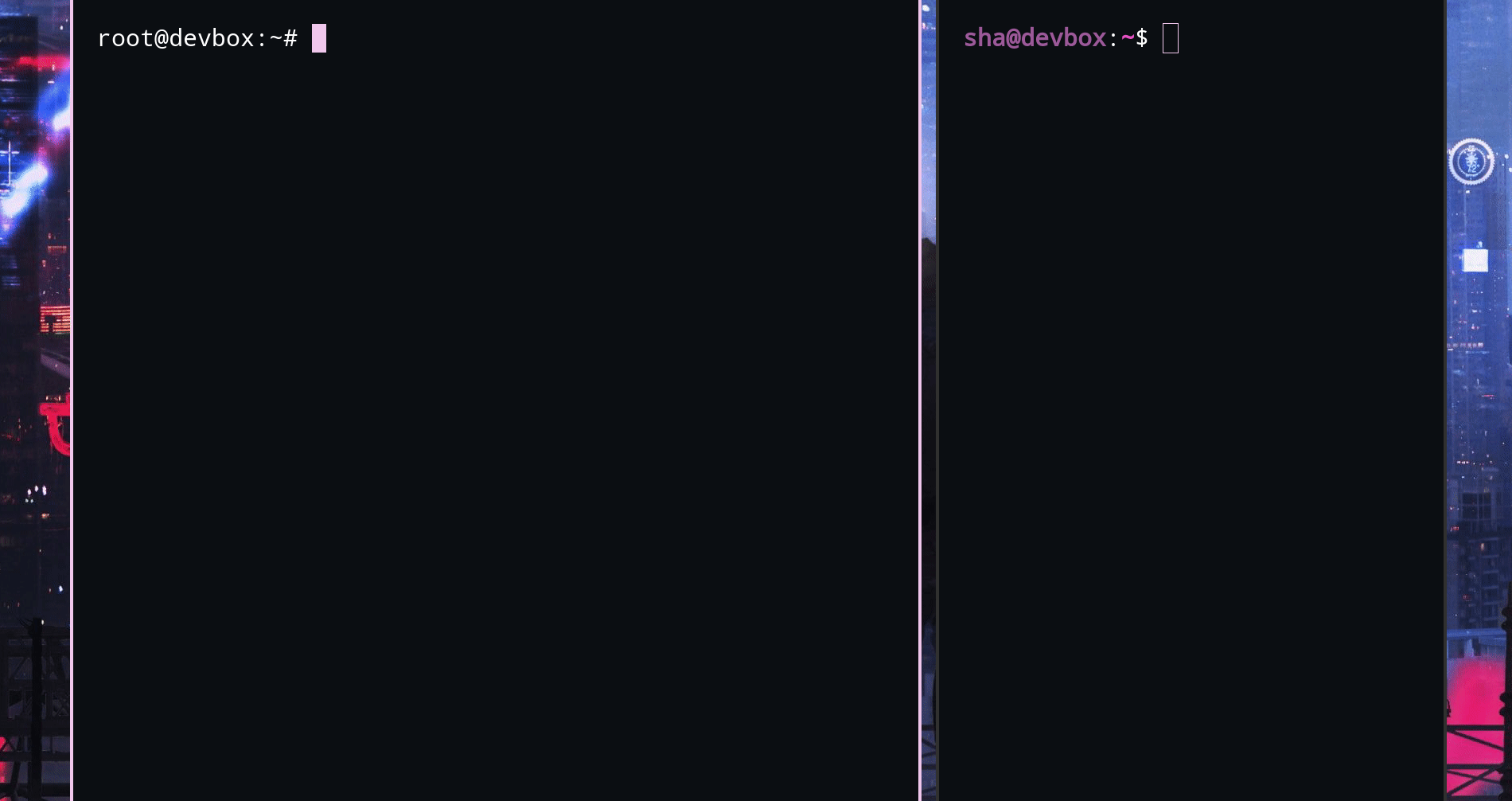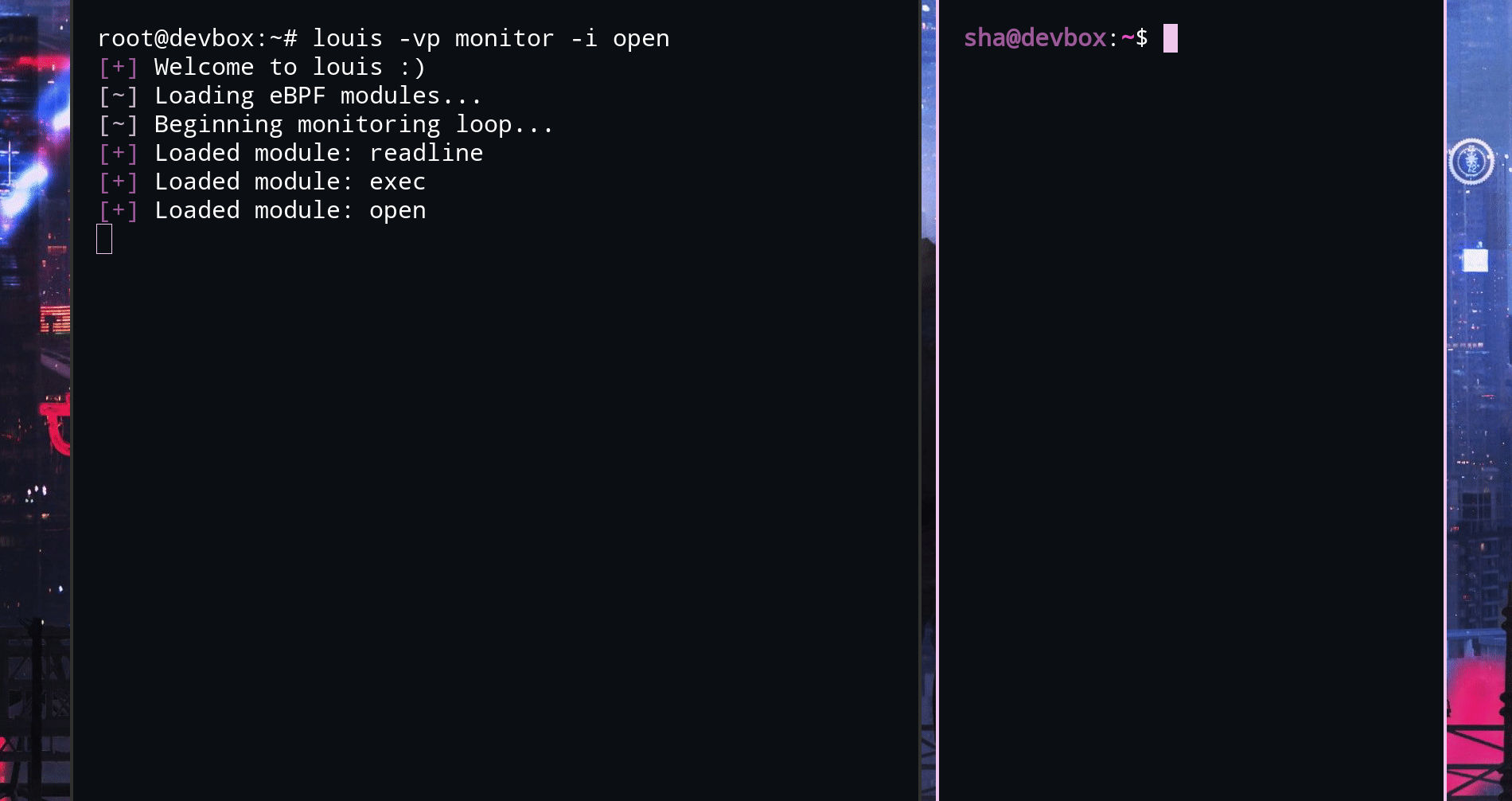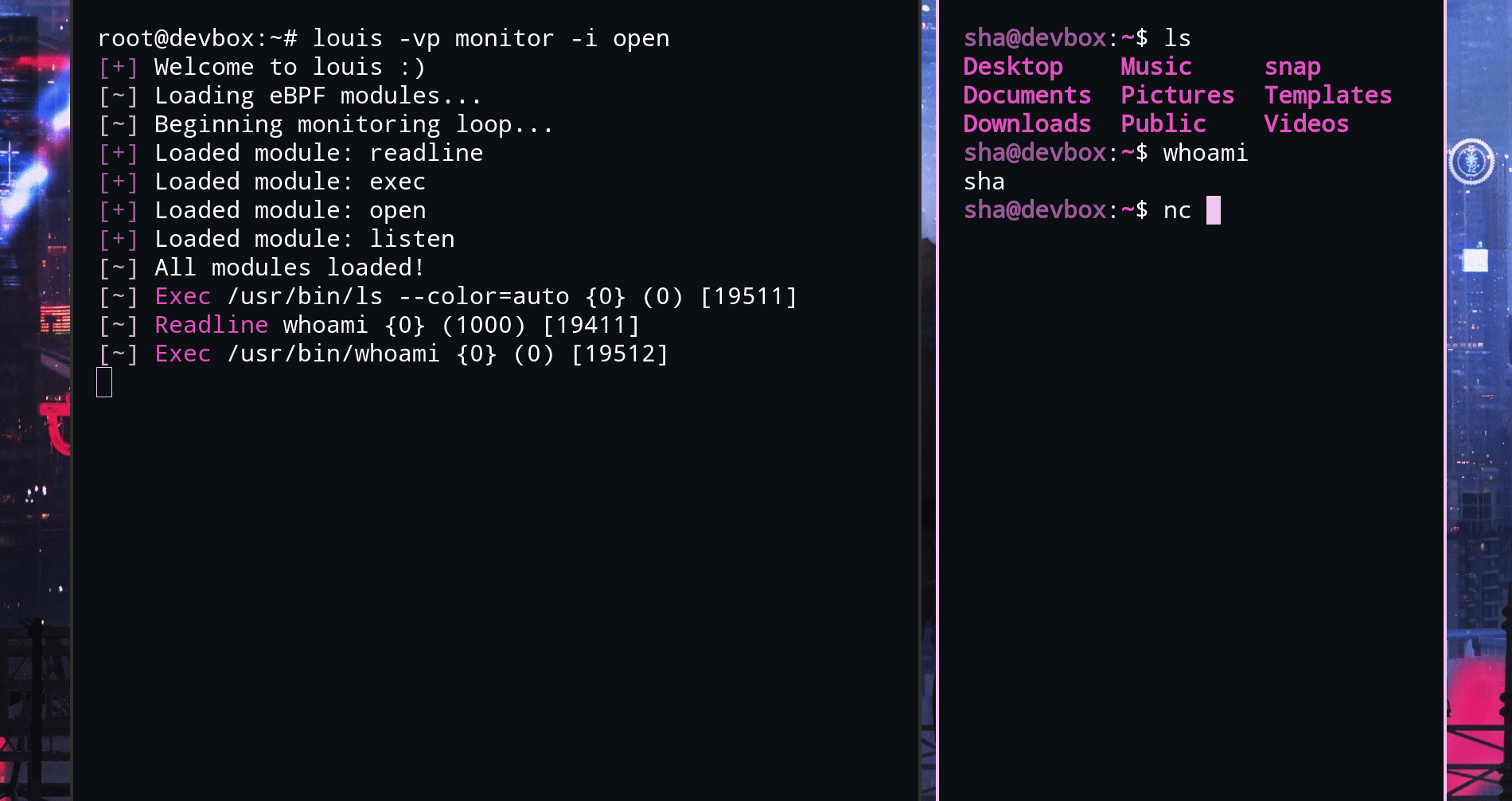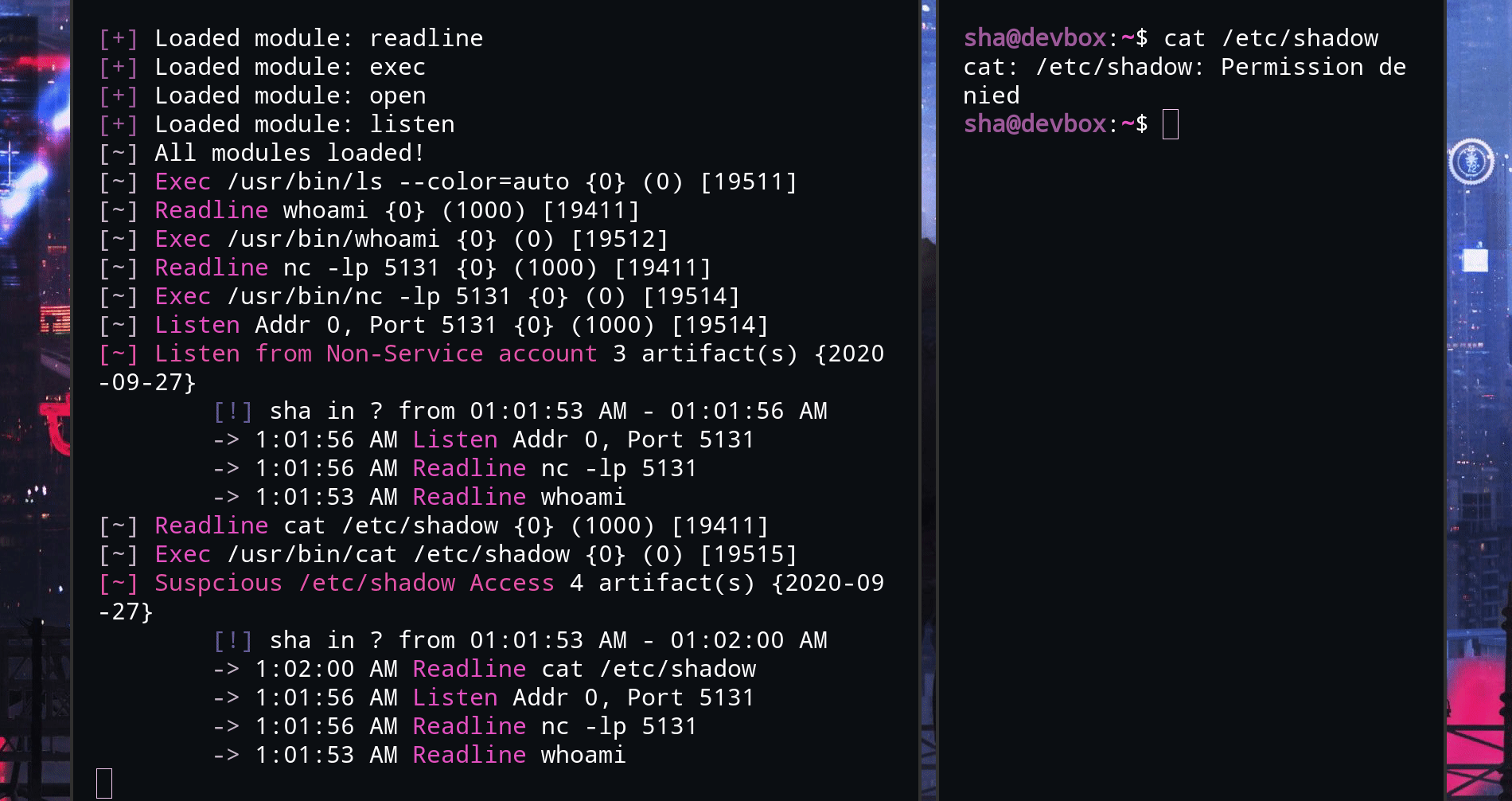
At this point, the jank really started coming out and making me doubt my choice of technology stack. For example, I saw a lot of duplicated code in my C snippets, so I made a home-brewed "macro" system, AKA, variables.
I would turn:
int syscall__openat(struct pt_regs *ctx,
int dfd,
const char __user *filename,
int flags,
umode_t mode)
{
struct event_t event = {};
struct task_struct *task;
task = (struct task_struct *)bpf_get_current_task();
event.pid = bpf_get_current_pid_tgid() >> 32;
event.ppid = task->real_parent->tgid;
bpf_probe_read_str(&event.filename, sizeof(event.filename), \
filename);
event.dfd = dfd;
event.flags = flags;
event.ret = ` + strconv.Itoa(eventNormal) + `;
events.perf_submit(ctx, &event, sizeof(struct event_t));
return 0;
}
int do_ret_sys_openat(struct pt_regs *ctx) {
struct event_t event = {};
struct task_struct *task;
task = (struct task_struct *)bpf_get_current_task();
event.pid = bpf_get_current_pid_tgid() >> 32;
event.ppid = task->real_parent->tgid;
event.retval = PT_REGS_RC(ctx);
event.ret = ` + strconv.Itoa(eventRet) + `;
events.perf_submit(ctx, &event, sizeof(event));
return 0;
}...into...
syscall__openat(struct pt_regs *ctx,
int dfd,
const char __user *filename,
int flags,
umode_t mode)
{
`+gatherStr+`
`+getPwd+`
bpf_probe_read_str(&event.filename, sizeof(event.filename), \
filename);
event.dfd = dfd;
event.flags = flags;
`+submitNormal+`
}
int do_ret_sys_openat(struct pt_regs *ctx) {
`+gatherStr+`
`+retStr+`
}But then, a different event collection module might need a slightly different use of these macros, and for most changes I'd have to edit all the modules anyway, and the debug cycle for the C-in-Go code was nauseating. I even tried implementing an interface to wrap around the binary/fixed array data that bcc would output, and it did not mesh well with how you commonly handle data in Go.
In short, I got it to work (kind of). And after that I felt like Frankenstein and kind of wanted to send Louis to live on a farm. In any case, source here.
Future Work
Although the idea still interests me a lot, at the moment, I don't see myself working on it further.
First, deploying louis is hard. Due to using BCC, like with kernel modules, if you don't compile on the machine, it's kind of a crapshoot if it'll work. That makes it much less feasible for competitions like CCDC, where you have no clue what environment you'll be dropped in to, and what's broken in it. Using go makes this issue worse unfortunately, since it just adds its baggage onto C.
Secondly, eBPF and the features I'm using in it, are lacking a lot of support on older kernels (read about the library and features here).
Finally, all that's left is to really write a bunch of rules. Since I won't be using this niche use-case tool for CCDC due to the above problems, I don't think there's much utility in improving upon the PoC.
So, eBPF and the BCC are super cool, and I learned a bunch about Linux. As always, it was a great experience working on this project, and seeing how an idea clashes and merges with reality. And I am eternally grateful to the wonderful people that write these amazing projects, articles, and pieces of documentation, to release them for free on the internet, for anyone who wants to read them.
If I wanted this project to be viable, I might pivot to using the pre-existing and compiled BCC tools glued together with bash, or something similar. Or, I might look more into using ftrace or older event monitoring systems. It may be more wise to use a more mature solution like sysdig's falco, or the slew of other 'cloud'-focused tools that accomplish similar things. But that's just not as fun.
Or, I guess, get better at reading logs.
- Windows EDR with a similar goal, BLUESPAWN, pushed the National CCDC Red Team to write a "counter" program, which was called "REDSPAWN." No source code for this since the only info we have is a slide during the NCCDC Red Team debrief. Of course, this is funny because, louis is not nearly effective enough to warrant such a response. ↩︎
- Fairly safe, in any case. As safe as anything involving a bytecode validator and C is expected to be (CVE-2021-3490). ↩︎